
随着数字化时代的来临,PDF格式的文档逐渐成为人们学习和工作中常用的文件类型。然而,为了更好地管理和利用这些PDF文档中的知识,我们需要将其转化为可编辑和可搜索的数字文本。本文将探讨以电脑识别PDF数字教程为主题,介绍其重要性和应用。

PDF识别的定义及意义
1.1PDF识别的概念和定义:PDF识别是指利用电脑技术将PDF文档中的文字内容提取出来,并转化为可编辑和可搜索的数字文本。
1.2提高学习效率:通过电脑识别PDF,我们可以快速搜索和定位所需知识,大大提高学习效率。
电脑识别PDF的方法与技巧
2.1OCR技术介绍:OCR(OpticalCharacterRecognition)光学字符识别技术是实现电脑识别PDF的核心技术。
2.2选择合适的OCR软件:根据个人需求和使用场景选择合适的OCR软件,如AdobeAcrobat、ABBYYFineReader等。
电脑识别PDF的步骤与操作
3.1安装和打开OCR软件:下载并安装合适的OCR软件,然后打开该软件。
3.2导入PDF文件:在OCR软件中选择导入文件功能,将需要识别的PDF文件导入软件。
优化PDF识别结果的方法
4.1检查识别结果:在识别完成后,对识别结果进行仔细检查,确保没有错漏。
4.2调整识别设置:根据需要,调整OCR软件的识别设置,提高识别精度。
电脑识别PDF的应用场景
5.1教育领域:学生可以利用电脑识别PDF进行知识整理和学习笔记的制作。
5.2研究工作:科研人员可以通过电脑识别PDF实现对大量文献资料的快速查找和整理。
5.3商务办公:职场人士可以利用电脑识别PDF提高工作效率,方便信息管理和搜索。
电脑识别PDF的优势与局限性
6.1优势:电脑识别PDF能够大幅提高知识管理效率,便于搜索和整理。
6.2局限性:对于复杂的PDF文档,如图片或手写内容较多的文档,识别效果可能不理想。
未来发展趋势及展望
7.1深度学习技术在OCR领域的应用:随着深度学习技术的不断发展,将为电脑识别PDF提供更加准确和智能的识别结果。
7.2云端OCR服务的兴起:未来,云端OCR服务将成为一种趋势,提供更加便捷和高效的PDF识别服务。
电脑识别PDF数字教程的重要性在于提升学习和工作的效率,实现数字化知识管理。通过选择合适的OCR软件,按照一定的步骤和操作,我们可以将PDF文档转化为可编辑和可搜索的数字文本。然而,电脑识别PDF也存在一定的局限性,需要根据实际情况进行优化和调整。未来,随着技术的不断发展,电脑识别PDF将越来越智能化和高效化。
当我们的戴尔电脑遇到一些故障时,如系统崩溃、启动错误或者无法进入操作...

在现今的社交媒体时代,我们拍摄和分享照片的频率越来越高。很多人喜欢在...
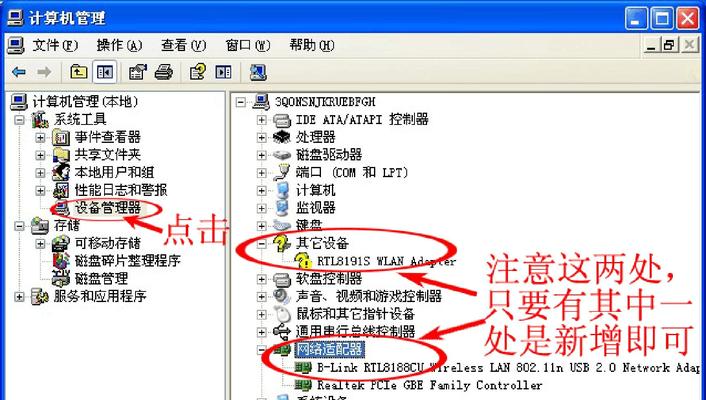
在使用电脑过程中,我们时常遇到各种驱动问题,这些问题往往会给我们的正...

随着智能手机的普及,手机成为人们生活中必不可少的工具。然而,我们经常...
随着手机使用的普及,人们对于手机应用程序的需求也日益增加。作为一款流...
